!!! Understanding the target schema/table
Understanding the structure of the target schema is of utmost importance. The forthcoming practical example entails the loading of data into a Data Warehouse. This process is characterized by its periodic execution at predetermined intervals, rather than being an ongoing process conducted continuously throughout the day.
It is executed at specific junctures, often singularly, encompassing the entirety of the process for all tables involved. However, comprehending the destination database is indispensable, as the destination tables entail relationships of foreign keys. Consequently, there exists a requisite sequence for loading, a sequence imperative for the analyst orchestrating the loading process to apprehend.
Consider the example provided herewith. It comprises three tables: a customer table, a product table, and a table for movements. Each table is devoid of data. Subsequently, a process is initiated to incorporate data into the product table.
The said process executes successfully, culminating in the recording of data within the table. Subsequently, a process is initiated to incorporate data into the movements table. However, this process encounters an error.
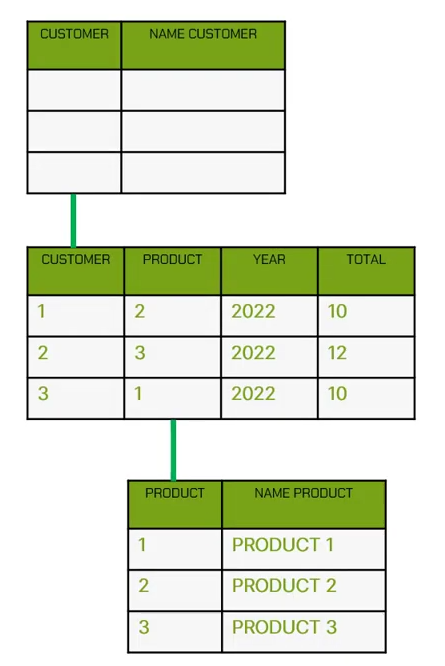
The cause? The customer table remains void of data, and a relationship exists between the customer field within the customer table and the corresponding field within the movements table. As per the tenets of relational database management, it is imperative to include customer data before any data can be inserted into the customer field within the movements table. Hence, precedence is accorded to the loading of the customer table prior to the movements table.
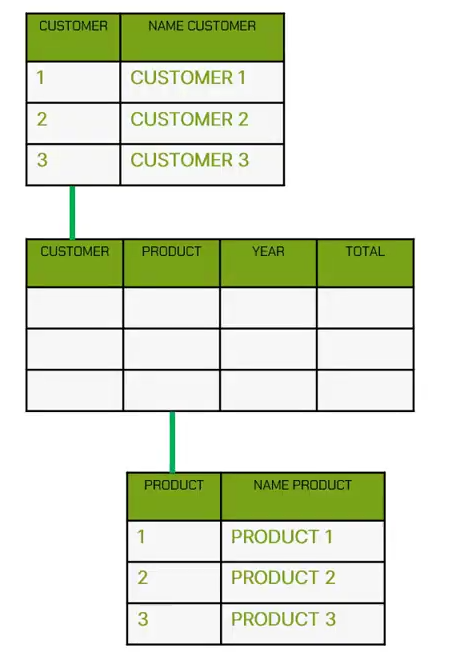
Henceforth, understanding the interrelationships of the tables within the destination databases is paramount to ascertain the loading sequence within the ETL (Extract, Transform, Load) process. Each database Integrated Development Environment (IDE) provides distinct methodologies for visualizing the sequence of tables. One such methodology involves graphical examination of the schema to delineate the sequencing of operations.
Nevertheless, graphical analysis may prove challenging in instances where numerous tables are involved. This information may be obtained via database management or through an analysis of the foreign and primary keys associated with the respective tables. It is beyond the scope of this document to elaborate on the methodologies employed to acquire such information. Nonetheless, the outcome of said investigation is presented herein.
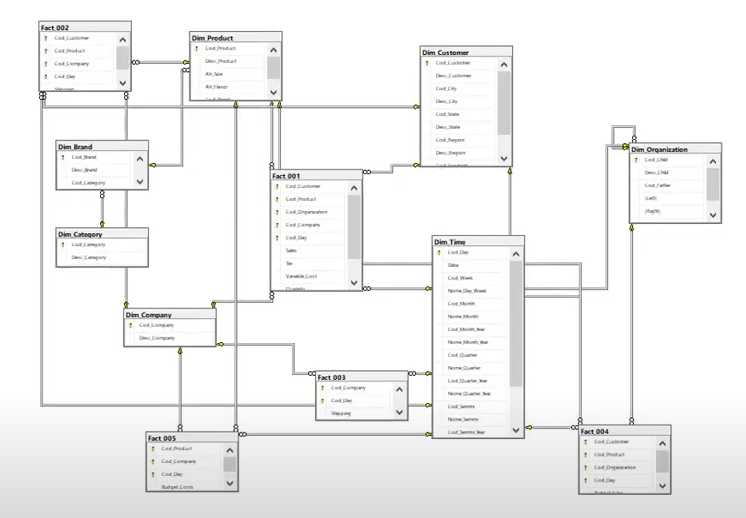
Thus, we delineate tables such as GIN COMPANY, GIN CUSTOMER, GIN ORGANIZATION, and GIN TIME, which are contingent solely upon the loading of the sources. Conversely, the GIN CATEGORY table relies solely on data sourced from external entities. Furthermore, for GIN BRAND, it is imperative to load GIN CATEGORY beforehand, and similarly, for loading GIN PRODUCT, the prior loading of GIN BRAND is requisite. In the context of fact tables, it is essential that all dimensions are loaded antecedent to the loading of FACT 1, 2, 3, 4, and 5.
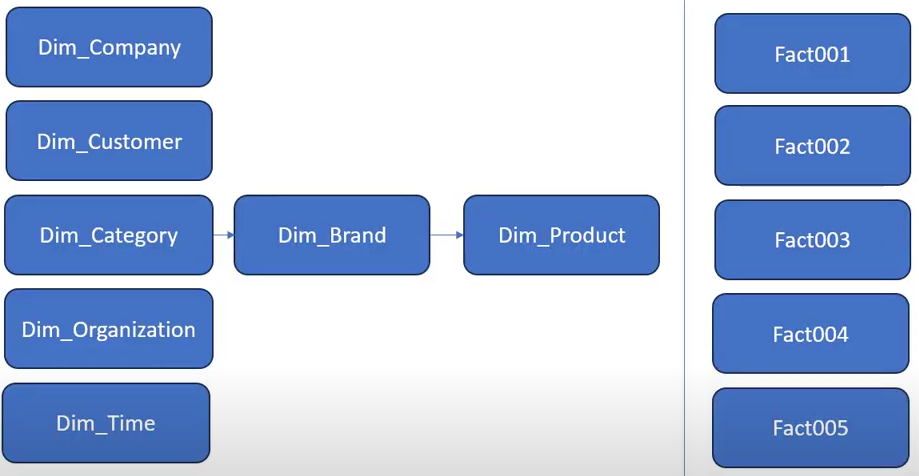
Moreover, subsequent to the determination of the loading sequence, it becomes imperative to discern the data sources for each table. Commencing with the loading of the COMPANY dimension, an examination of the source files reveals that data for this table emanates from SQL queries encapsulated within the companies.txt file.