Product architecture
Let's talk about product architecture. This is the goal of PIS, Metaware or Connware: Data from any source to any target. Of course, this goal is difficult to achieve, but as new updates are made available to the product, it gets closer and closer. But there's more: the product isn't just about data integration. We can think of using the product for data migration, data conversion, bidirectional integration, EPL for Data Warehouse, Webservices catalog and much more. As you progress through the documentation, you'll discover the product's many features for handling data.
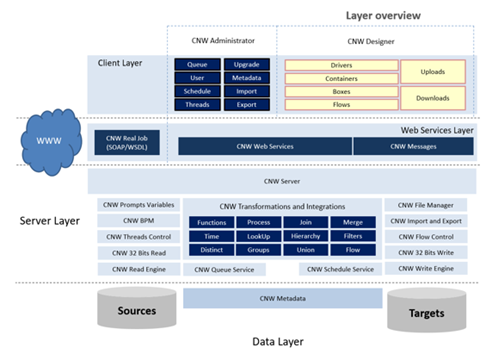
In the figure above we can see the product architecture. From now on, we will refer to it as PIS. However, as already mentioned, what is presented here applies to Metaware, Connware and Cerensa Integrator. Coming back, we can highlight three layers that make up the product. Client Layer. This layer consists of an application, or an app, which represents the presentation layer. Two types of user access this layer, the administrator user and the user who will design the PIS models. This application is designed to run in a Windows environment and does not require a formal installation, simply copying the files to a specific directory, although there is a setup and an application to install this application.
The other layer is the webservices layer. This layer communicates between the client application and the server. It is done via webservices. This means that "Client-Server" communication is not over TCP and IP, but over HTTP or HTTPS protocol, via an intranet or the internet. The application server on which these webservices will run must be the Internet Information Service, or IIS.
Now we have the server layer. This layer is where the product's intelligence lies. It is through the server that the data sources and model metadata will be accessed. Finally, the data layer. We can include the metadata database in this layer. This must be implemented using SQL Server. If you don't have a license for this product, you can use SQL Server Express, as the size of the metadata database is not so large. Of course, if you use a corporate SQL Server database, performance increases considerably. The metadata data is stored in JSON format, simulating an unstructured NoSQL database in SQL Server.
This form of metadata storage was chosen because it allows the entire class to be saved within the database. This layer can also include the data sources that will be involved in the ETL and integration processes. PIS Administrator is an application located in the "Client" layer. This is where the environment is administered. The PIS environment administrator can do the following things. Manage users with access to the system, as well as their security privileges. Manage processing queues. Through this interface, the administrator user can delete threads that have not yet been executed, as well as change their priority. The PIS administrator environment can manage the thread processes, drop threads that they want to be executed more, schedule processes to be executed at certain times, execute processes punctually, among other things.
In administration mode, you can configure new metadata, delete existing metadata, clear logs, install Windows services: Schedule and Thread Services, backup and restore metadata data, and transfer the environment from one location to another. For example, moving a model from a development environment to production.
PIS Designer is the application where the ETL and integration processes will be designed. Everything done there will be recorded in the metadata layer, on the server, via Webservices. The process will be designed using four groups of components that form a PIS model. Driver, Container, Boxes and Flows. In the course of this documentation, these concepts will be explained in more detail.
Through a special process in the client application, files can be transported between the client and the server. We have already mentioned that the Webservices layer handles communication between the client and the server. But this layer is much more than just a bridge between the two layers of software. PIS Webservices makes it very easy to create Endpoints that make references to any PIS component to be called via another tool that supports Webservices in RESTful format.
You can create Endpoints that simply access data managed by the PIS model. Or another that returns the data after executing one or more transformations. Or we can initialize an integration process asynchronously or asynchronously through other Webservices composed in the catalog created by the PIS user himself. This greatly expands the use of the tool beyond software that designs ETL and integration processes.
The PIS Server is the mode that receives and sends communication requests between the client and the server via the PIS Webservices. It manages all the product's intelligence modules. It is through the modules contained in the PIS Server that the product will work and execute its processes.
Let's talk about the PIS Read Engine. The PIS server has a specialized data reading engine for each type of data source. We can highlight the database reading engine via ODBC or directly using the NET API, in Microsoft SQL Server, Oracle, MySQL, PostgreSQL and many more. But we can also highlight reading data from text files, Excel spreadsheets, files in XML format and files in JSON format. These files can be in a server directory, on FTP sites or on HTTP pages.
However, it is possible to read data via Webservices, in the RESTful or SOAP standard. We can also read from unstructured or non-SQL databases such as MongoDB, ERPs such as Proteus and Totvs, multidimensional databases such as Microsoft OLAP Analysis Services or SAP BW and specialist databases such as Exact. It is possible for the development team to customize some kind of special read driver for a type of data source not previously mapped.
PIS Write Engine. This is the component that writes the data to the target source. In this case, almost all the sources where we can read data can also be written. The word "almost" has been highlighted because not all data sources can be written to. A specific case is when the target data source is an ERP with its specialist tables. But for all Microsoft SQL Server, Oracle, MySQL and PostgreSQL relational databases, the write mechanism has an intelligence where, for example, based on a primary key, the PIS can know whether to include a new row, replace or delete an existing row.
There are also mechanisms for batch reads so that, when necessary, many records can be read in a short time. During the write process configuration mechanism, these load policies can be configured. But data can also be written in JSON, Excel or XML text file format. These files can be uploaded to FTP or HTTP sites or sent via webservices to other environments.
PIS is a 64-bit tool, but we can find databases whose communication drivers are 32-bit. For this, we have a special module that reads them. For the user who designs and executes the integration processes, the management of whether we are reading 64-bits or 32-bits is automatic, as long as it is properly configured in the design properties of the ETL or integration process.
The PIS 32-bit Writer performs the same process as the reading process, writing to a 32-bit database transparently. Every ETL or integration process designed by PIS, when executed, is redirected to a thread. The thread is the single, independent process that takes place on the server. A process may run several threads, either sequentially or in parallel. We can also have several threads from several processes running at the same time on a single server. PIS Threads Control controls all these processes. From a control panel, you can see which threads are running, their estimated time of completion, whether the thread has executed the process successfully or with error, you can view the processing log of a thread, as well as kill a thread that is being processed.
Through PIS BPM we can monitor the statistics of the data being read. This allows us to understand whether our data extraction is correct or not. PIS Prompt Variables allow you to create variables for the execution or configuration of any PIS process or component. We can, for example, create a Prompt variable that represents the location where a file will be saved, or represents the name of the table in which the data should be read, or the number of lines that will be written to the text file. Any configuration or parameter of any PIS component can be replaced by a Prompt Variable. These variables can be assigned single values or vectors to create loops associated with a function or formula or associate the set of values in a Prompt Variable with the result of a query to a data source. Let's say we want to read data from a set of cities. This list of cities could be a Prompt Variable based on a table in a database. Depending on how Prompt Variables are created, we can create integration templates and apply them in different environments, as long as these processes are similar. This considerably increases productivity when implementing integration processes on similar systems in different locations.
The PIS File Manager is a communication module with the client side that manages and stores the files that have been transported by the client through the upload or sends files back through the download process. During the development of an ETL integration project, we can encounter various implementation scenarios. We can have the processes built in a development environment which is then transported to a test environment and finally made available in production. Or we can develop an integration as if it were a template and then publish it in another environment that uses similar processes. We mentioned this when we talked about Prompt Variables. But it may also be necessary to create backups of the templates and then recover them, either to prevent possible losses or to create a repository of template versions. All this transfer of environments can be carried out with PIS Import-Export.
With this module, we can synchronize models from different environments. It has the possibility of preserving particularities in an environment that is being restored, such as environment variables and connection properties of data sources. It can also synchronize environments not only by including or changing objects between environments, but also by deleting objects in a target environment that have subsequently been deleted in a source environment.
PIS Flow will build a logical flow for executing the threads. In fact, a thread consists of executing what we call boxes. When a box is executed, it is directed to an instance of the thread server processor, which will be executed using certain machine resources, hardware, to do what was specified in the model design. It is in this module that we will determine the sequence in which the pits will be executed. We can determine execution sequentially, use execution branches, if a thread in a box gives an error, do one thing, if it does, do another, create loops to execute one or more groups of boxes, create subflows or subflows to execute a set of boxes repeatedly, wait for an event to happen to start processing a box and much more.
It is at this point that the execution of the flows is scheduled. We can schedule its execution to be carried out at a specific time, or run several times a day, for example, run every minute, or run in a loop forever or during a time interval. We can schedule execution for one or more days of the week, in the month or for some months of the year.
One of the services responsible for the PIS environment is Thread Services. In the figure we represent it as queue services, but it is the same thing. This service watches the queue of processes to be executed. When a process enters the queue, the service takes it and redirects it to a machine resource, hardware, so that it can be executed. The process can enter this queue through a manual order from a user or through PIS Scheduler Services.
During process execution, they can be observed using the PIS Thread Monitor. In it we can take down undesirable processes, monitor the processing of a process in detail, check logs in order to detect errors and delete old logs.
PIS Scheduler Services, here we have another server service, which executes processes based on a schedule. This service does not specifically execute the process, in fact it transports to the process queue the same one that is observed by PIS thread services, the process on a given day and time. Then, the service will execute it respecting this queue. Processes can be scheduled on a specific day and time, on a specific day of the month, days of the week and even in just some months of the year. The process can be repeated periodically, every number of seconds and for a certain period. Also, all appointments can have a validity period.
Here lies the engine of ETL and integration processes. Through PIS Transformations, the data will be modified to be stored in the target data source in the correct format. Many modules and transformation processes can be implemented. We will mention some of them below.
Transformation functions: There is a vast catalog of transformation functions, categorized by text manipulation functions, dates, numbers, tables, operating system functions, random code generation and special functions, related to calculations and code format validations.
Special functions: However, if no function in the catalog meets the need for the ETL integration process, it is possible to create your own transformation functions through a development IDE within PIS itself, or import Visual Studio .NET program codes to meet the requirements. the needs for transformations. This module allows you to add external DLLs that have business intelligence and enrich your own functions.
Processing functions: They have the same principle as special functions, but here, instead of the result being a certain value, text or date, the result is a logical expression, true or false. We use processing functions to test and make logical detours in the ETL integration process execution flow, as well as to perform more complex data manipulation processes.
Time Intelligence: These are transformations that create calendars based on dates that are previously stipulated or based on data contained in the source or destination. We can stipulate data in the Gregorian calendar, obtaining consolidation points, such as week, month, quarter, semester and year, or work with Hindu, Islamic or Lunar calendars.
Hierarchies: There are some transformations dedicated to assembling or dismantling hierarchies. They can transform a denormalized hierarchy into a table in a parent-children format or vice versa. They can also automatically implement lookup processes to create sequential codes or in text format in Data Warehouse dimensions.
Table manipulation processes, such as adding or deleting new columns, adding new rows, creating new columns using mathematical formulas and logical expressions, performing data ordering, creating primary keys, testing the integrity of data based on a foreign key, performing union of tables, connection between tables, presenting the different lines of tables, grouping using criteria of sums, maximums, minimums and averages, creating conditional processes, and many other things not mentioned here.
All information is stored in metadata through Pis Metadata. Data is not saved in a traditional table in a relational database. Pis Metadata tables have a layout similar to what is shown here in the figure to the side. The table will always have a unique identifier, whose field will be called _ID. Then, it will have some reference fields to other entities. Depending on each type of metadata, this reference field will be different. However, the main field is another, called JSON-STR. This field contains the object serialized by the program and saved in the table. By searching for the content of this field and observing it in the specialized JSON editor, you will be able to see all the metadata properties of that element associated with the table.