- Product Dimension Loading Process
Understanding the Product Dimension Loading Process
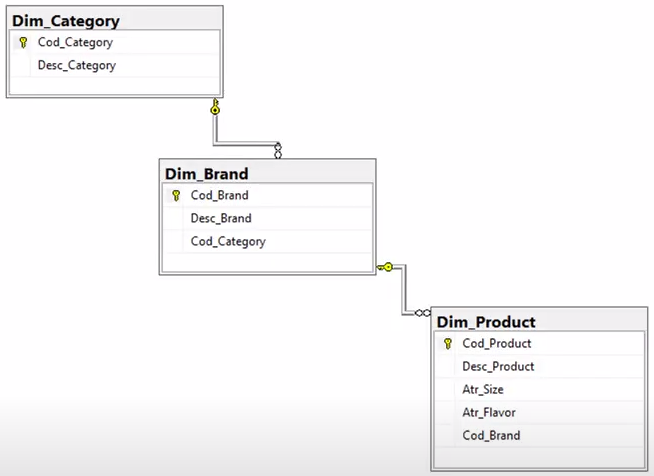
This section delves into the intricacies of loading the product dimension, a pivotal step in our data integration efforts. The process entails integrating data from three interconnected tables, as depicted above. These tables, namely Gene Category, Gene Brand, and Gene Product, are interlinked through foreign keys, necessitating a methodical approach to data inclusion.
The initial step involves populating the Gene Category table with product categories. Subsequently, data insertion proceeds to the Gene Brand table, followed by the Gene Product table. Adherence to this sequential order is imperative to maintain data integrity and relational consistency.
An essential consideration in this process is the selection of appropriate data sources. A CSV file containing brand and category information, alongside an Excel spreadsheet housing product data, serve as the primary sources. While the CSV file provides brand and category details, the Excel spreadsheet offers product codes and descriptions, facilitating a comprehensive data integration strategy.
Transformations are integral to this process, although specific methodologies may vary. For instance, data extraction from the CSV file involves retrieving category information from the second column and associating it with the appropriate descriptors in the destination table. The generation of unique codes for categories is accomplished through a technique known as Lockup, ensuring data coherence and consistency.
Similar procedures are applied to the Gene Brand table, where brand details are extracted from the CSV file and linked to their corresponding categories. The Lockup process assigns distinctive codes to brands, enhancing data organization and accessibility.
Moving to the product dimension, the SKU and Description columns from the Excel spreadsheet are directly integrated into the Improduct table, providing essential product identifiers and descriptions. Additional data fields, such as size and flavor, are extracted from the product descriptions and stored accordingly.
Notably, the integration of brand descriptors involves referencing the GeneBrand table to retrieve assigned codes, thereby establishing cohesive relationships between products and brands.
By meticulously adhering to these procedures and leveraging appropriate data transformation techniques, we ensure the seamless integration of product data into our Data Warehouse. This systematic approach lays the foundation for comprehensive data analysis and informed decision-making.
As we progress through this loading process, we remain committed to maintaining data integrity and optimizing the efficiency of our data integration efforts. Stay tuned for further updates on our journey toward unlocking actionable insights from our data repositories.